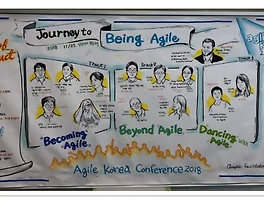
Development (305) 썸네일형 리스트형 Agile Korea Conference 2018 참석 후기 회사 건물에서 진행되었던 Agile Korea Conference 2018 에 다녀왔다. 신입사원 때부터 들어왔던 Agile 이지만 아직도 어색하고 제대로 하고 있는지 의문이 들 때가 많아서 이번 컨퍼런스에서 해답을 얻을 수 있을까라는 기대감이 있었다. ( 주관적으로 생각해서 받아 적은 메모를 바탕으로 작성한 후기 입니다. 잘못된 내용, 잘못 이해한 내용이 있을 수 있습니다. ^^) "Journey to Being Agile" 이번 conference 의 슬로건이다. 대체 Being Agile 이 뭐지??? 부디 컨퍼런스가 끝날때 쯤에는 그 의미를 알수 있기를 바란다. Lean Coffee키노트가 시작 되기 전에 Lean Coffee 라는 세션이 있었다. 상세 일정에 나와있길래 뭔지 몰라서 가기전에 한번.. [K8S] Kubernetes Object Management 에 대해서 살펴보자. Kubernetes를 사용하면서 자주 사용하는게 kubectl 명령어 이다. 그리고 그중에서 컨테이너를 생성할때 항상 kubectl create 명령어를 사용했다. 그런데 사용하다보니 어떤 글에는 create 를 사용하고 어디에서는 apply 를 사용하는 것을 보게 되었다. 그래서 이 차이점이 궁금해서 이렇게 정리하게 되었다. 아래 내용들은 kubernetes document 에서 요약한 내용들이다. https://kubernetes.io/docs/concepts/overview/object-management-kubectl/overview/ Kubernetes 에서 Object Management 에는 3가지가 있다. Management technique Operates on Recommended en.. SpringOne Tour 참석 후기 지난번 Google Summit 에 이어 이번에는 피보탈에서 주최하는 SpringOne Tour 세미나에 참석을 했다. https://springonetour.io/2018/seoul 우연히 Facebook 타임라인에 뜬 세미나 일정과 Agenda 를 보고 신청을 했었다. Spring 관련 세미나라서 내용에 대한 기대가 컸다. 세미나의 전체적인 주제는 Reactive 와 Cloud 관련 내용들이 많이 있었다. 회사에서 많이 쓰지는 않는 내용들이었지만 그래도 공부하면서 봤었던 유투브에서 봤던 내용들이어서 어느정도 이해할 수 있었다. 그리고 대부분 라이브 코딩이 포함되어 있어서 오히려 더 도움이 됐다. 세션 요약1. Reactive Spring with Spring Boot 2.0 - Mark Heckler.. [K8S] Kubernetes 기초 개념 정리 Cluster- Master, Node 2가지 타입의 리소스가 존재한다.- Master : cluster를 관리한다. - Node : Worker Machine 으로 제공되는 VM 또는 물리적 컴퓨터이다. 각각의 Node 는 Node 를 관리하고 Kubernetes master와 커뮤니케이션을 할수 있는 Kubelet 이라는 agent 를 가지고 있다. Node 는 master 가 노출시켜놓은 Kubernetes API 를 사용해서 통신을 한다. https://kubernetes.io/docs/tutorials/kubernetes-basics/create-cluster/cluster-intro/Pod- Deployment 를 생성하게 되면 Deployment는 Pod 를 생성하고 그 안에 Containe.. Google Cloud Summit 2018 후기 10월 25일 Google Cloud Summit 2018 이 삼성역 코엑스에서 열렸다. https://cloudplatformonline.com/2018-Summit-Korea-Home.html 페이스북으로 올라온 글을 보고 신청기간에 등록을 해서 참석하게 되었다. Google Cloud Summit 세미나 할때마다 자주 가는 코엑스. 처음에 돌아다닐때에는 위를 보지 않아서 오른쪽 그림이 걸려있는지 몰랐다. -_-;;. 국내에서 처음 하는 Google Cloud Summit 이어서 인지 전에 와봤던 다른 세미나보다 현수막들이 많이 달려 있는 느낌이었다. 행사 일정이다. 파란색의 낯익은 로고를 보고 정말 의외라고 생각했다. 키노트 하는 오디토리움 내부에서 봤던 로고이다. 개인적으로 왼쪽 로고와 색깔이 맘.. [GCP] Google Cloud 컨테이너 레지스트리에 이미지 push 하기 먼저 Dockerfile 이 있다고 가정한다. 내가 만든 이미지는 spring boot 어플리케이션이다. Dockerfile 12345FROM openjdk:8-jdk-alpineVOLUME /tmpCOPY ./build/libs/mail-0.0.1-SNAPSHOT.jar app.jarRUN echo 'Mail Service running'ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]cs 이제 이 Dockerfile 을 빌드를 한다. sudo docker build -t asia.gcr.io/[GOOGLE_PROJECT_ID]/mail-service:v1 . docker build : 컨테이너를 만드는 명령어.. [Gradle] gradle build error tool.jar... valid JDK Ubuntu 에서 Gradle 빌드 하는데 Error 가 났다. * What went wrong:Execution failed for task ':compileJava'.> Could not find tools.jar. Please check that /usr/lib/jvm/java-8-openjdk-amd64 contains a valid JDK installation.Error 내용을 보면 뭔가 찾을수 없다고 나온다.. tools.jar 파일.일단 설치된 자바 버전을 확인해 보자.java -versionopenjdk version "1.8.0_181"OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-0ubuntu0.16.04.1-b13)OpenJDK 6.. [Gradle]Ubuntu 에서 Gradle 설치하기 Ubuntu 에서 gradle 설치를 해보자.설치 방법은 정말 간단하다.sudo apt-get install gradle$ sudo apt-get install gradleReading package lists... DoneBuilding dependency tree Reading state information... DoneThe following additional packages will be installed:이렇게 하면 설치가 쭉~~ 시작된다.gradle -v------------------------------------------------------------Gradle 2.10------------------------------------------------------------Bui.. [Kafka]Window 에서 Kafka 설치후 실행해보기 Window 환경에서 Kafka 를 설치해보고 실행 해보려고 한다. 1. 설치설치는 간단하다. 아래의 URL 로 가서 다운로드 받은후 압축 풀면 설치 끝이다. https://kafka.apache.org/downloads 2. 실행Kafka 는 Zookeeper 를 사용하기 때문에 먼저 zookeeper 부터 실행을 한다. 카프카 설치 디렉터리로 이동해 보면 sh 파일들이 있는데 Window 환경에서 실행하는 실행파일들은 windows 폴더 아래에 따로 모아져 있다. zookeeper 실행카프카설치디렉터리\bin\windows\zookeeper-server-start.bat ../../config/zookeeper.properties kafka server 실행카프카설치디렉터리\bin\windows\ka.. Google Cloud Hackathon 간단한 후기 올해 초부터 시작했던 Google Cloud Study 가 어느덧 3번째 과정이 끝났다. 2018/05/15 - [Development/Tech&Seminar] - Google Cloud Study Jams 후기 맨 처음에는 Qwiklabs 을 통해서 공부를 했었다. 그리고 두번 째 Advanced 과정에서는 Coursera 에 있는 GCP 과정을 수강을 했다. Qwiklabs 이나 Coursera 과정에 분명 실습 과정이 있긴 했지만 실습이 끝난 후에는 기억이 나지 않았다. ^^;;; 그래서 아쉬움이 많이 남긴 했었는데 이번에는 정말 사용해야 할 만한 이유가 생겼다. 바로 3번째 과정이 Cloud Hackathon 이라는 이름으로 프로그램을 직접 GCP 에 올려서 진행을 해야 했기 때문이다. 우선 처음.. 이전 1 ··· 13 14 15 16 17 18 19 ··· 31 다음