728x90
반응형
2024.08.20 - [Development/Python] - Python 웹 스크래핑 하기
Python 웹 스크래핑 하기
2~3주에 한번씩 책을 20권 이상 빌리다 보니 이미 빌린 책인지 아닌지 확인해야 할 일들이 생겼다. 일반 도서는 상관이 없었는데 잡지 같은 경우 구분하기가 상당히 불편했다. 이유는 대여 목록해
blusky10.tistory.com
기존 글에 이어서 웹 스크래핑 한 정보를 다시 한번 더 가공해보려고 한다. 우선 먼저 글에서는 스크래핑을 통해서 url 을 추출했다. 이번에는 추출한 url 웹페이지에 있는 정보를 가져와보려고 한다.
def get_book_info_from_url(url:str) :
detail_response = requests.get(url, verify=False, cookies=cookies)
# 상세 페이지 파싱
detail_soup = BeautifulSoup(detail_response.text, 'html.parser')
# 예: 상세 페이지의 특정 데이터 추출 (예: 제목과 본문)
title_search_result = detail_soup.find_all('b', id="bookTitleInfo")
if len(title_search_result) > 0:
title = title_search_result[0].text
reg_num = detail_soup.find_all('li', class_="og")[0].text
print(f'title: {title}, reg_num: {reg_num}')
book = {
"title": title,
"registration_number": reg_num
}
books.append(book)위 코드는 url 에 해당하는 웹페이지(책 상세페이지) 에서 책 이름과 등록번호를 가져오는 함수를 정의한 것이다.
- 파라메터로 전달된 url 페이지를 html.parser 를 이용해서 파싱을 한다.
- 파싱된 페이지 정보에서 id 가 bookTitleInfo 를 찾는다.
- 만약 bookTitleInfo 가 존재 한다면 그 안에서 title 과 reg_num 을 찾는다.
- 실제로 html 정보는 다음과 같이 구성되어 있다.
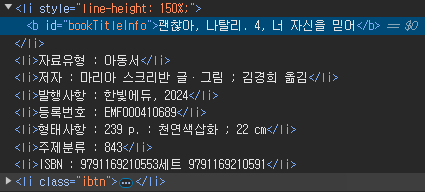
- 찾은 정보는 books 라는 list 에 저장한 다음 파일로 저장을 했다. 실제 파일에는 다음과 같은 형태로 저장되어있다. 위에서도 볼수 있듯이 li tag 안에 "등록번호" 라는 단어까지 같이 있어서 json 파일의 registration_number 에 "등록번호 : " 라는 값이 중복 저장됐다.
[
{
{
"title": "특별한 내가 될래요 : 인기 있고 칭찬받는 친구들의 비밀",
"registration_number": "등록번호 : EMF000392726"
}
]
728x90
반응형
'Development > Python' 카테고리의 다른 글
| [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (0) | 2024.08.27 |
|---|---|
| Python 웹 스크래핑 하기 (0) | 2024.08.20 |
| [Python] Blob Storage 에 Connection String 으로 연결하기 (0) | 2024.08.01 |
| python 으로 Azure blob storage 연결 (0) | 2024.07.12 |
| poetry 설정 및 패키지 추가 (0) | 2024.07.11 |

